What does the Robots.txt file mean for SEO?
What exactly is the robots.txt protocol?
Robots.txt protocol allows you to guide spiders on your website so they only crawl the pages you want them to crawl. Although this might seem contrary to the goals of SEO, preventing the spiders from exploring some of your content can actually be beneficial. For example, this might apply when you are building a new website, or if you have multiple versions of a page on your site and you do not want to get penalized for duplicate content.
The origins of the protocol can be traced back to the mid-1990s when early webmasters began to have concerns about what spiders visited their websites. The idea has grown to meet the needs of modern web designers and the current version will be accepted by the spiders sent from the major search engines.
Do I need robots.txt?
Since robots.txt tells search engine spiders not to crawl certain pages, some site owners might mistakenly think that this is a good way to keep certain information private. Unfortunately, although honest spiders, such as those from Google or Bing, will respect the protocol, there are plenty of malicious spiders that will not, and thus your information can still be stolen.
It is also possible for the information to end up indexed in other ways, such as another site linking to the content. If you have personal information, you should have much stronger security, such as through a firewall.
Where should robots.txt be located?
When using robots.txt, it is a good idea to be familiar with the basic symbols. A ‘*’ tells the spider that this command applies to all web crawlers. You can replace this with the name if a certain bot if you only want to prevent certain search engines from indexing a page. A ‘/’ will indicate that the rule applies to all the pages on a particular site. This symbol can be replaced with the name of a particular directory or page.
For example, if you want to tell all web crawlers to ignore all the pages on your site, then your command will look like:

If you want to tell all web crawlers to ignore a particular directory, the command will look like:
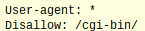
If you want to tell all web crawlers to ignore certain pages, you will write:
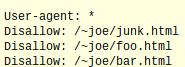
If you wanted to block only a particular bot from your site, then you modify the user-agent and write:
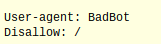
Finally, if you want to allow only one web crawler and block the rest, you will write:

The first part of the command tells Google it can explore the whole site, since there is nothing next to the disallow section. The second part of the command speaks to the rest of the bots, telling them to stay away.
It is a good idea to keep the following guidelines in mind:
- You always have to write robots.txt in lower case
- The commands must be located in the top-level directory of the web server
- You can only have one ‘disallow’ for each URL on the site
- Subdomains that have a common root domain need different robots.txt files
- Do not use spaces to separate the parameters of the command
Using the protocol is relatively straightforward, but simple typos can easily derail the commands. After you write your protocal, make sure to use the Google testing tool to see how the search engine giant will interpret your protocol.
When used wisely, robots.txt can be a valuable resource and help you control what and when search engine spiders explore your offerings.

<< Back to the SEO Glossary main page
What exactly is the robots.txt protocol?
Robots.txt protocol allows you to guide spiders on your website so they only crawl the pages you want them to crawl. Although this might seem contrary to the goals of SEO, preventing the spiders from exploring some of your content can actually be beneficial. For example, this might apply when you are building a new website, or if you have multiple versions of a page on your site and you do not want to get penalized for duplicate content.
The origins of the protocol can be traced back to the mid-1990s when early webmasters began to have concerns about what spiders visited their websites. The idea has grown to meet the needs of modern web designers and the current version will be accepted by the spiders sent from the major search engines.
Do I need robots.txt?
Since robots.txt tells search engine spiders not to crawl certain pages, some site owners might mistakenly think that this is a good way to keep certain information private. Unfortunately, although honest spiders, such as those from Google or Bing, will respect the protocol, there are plenty of malicious spiders that will not, and thus your information can still be stolen.
It is also possible for the information to end up indexed in other ways, such as another site linking to the content. If you have personal information, you should have much stronger security, such as through a firewall.
Where should robots.txt be located?
When using robots.txt, it is a good idea to be familiar with the basic symbols. A ‘*’ tells the spider that this command applies to all web crawlers. You can replace this with the name if a certain bot if you only want to prevent certain search engines from indexing a page. A ‘/’ will indicate that the rule applies to all the pages on a particular site. This symbol can be replaced with the name of a particular directory or page.
For example, if you want to tell all web crawlers to ignore all the pages on your site, then your command will look like:
If you want to tell all web crawlers to ignore a particular directory, the command will look like:
If you want to tell all web crawlers to ignore certain pages, you will write:
If you wanted to block only a particular bot from your site, then you modify the user-agent and write:
Finally, if you want to allow only one web crawler and block the rest, you will write:
The first part of the command tells Google it can explore the whole site, since there is nothing next to the disallow section. The second part of the command speaks to the rest of the bots, telling them to stay away.
It is a good idea to keep the following guidelines in mind:
- You always have to write robots.txt in lower case
- The commands must be located in the top-level directory of the web server
- You can only have one ‘disallow’ for each URL on the site
- Subdomains that have a common root domain need different robots.txt files
- Do not use spaces to separate the parameters of the command
Using the protocol is relatively straightforward, but simple typos can easily derail the commands. After you write your protocal, make sure to use the Google testing tool to see how the search engine giant will interpret your protocol.
When used wisely, robots.txt can be a valuable resource and help you control what and when search engine spiders explore your offerings.