
The Value of Robots.txt: How Does It Help SEO?
The origins of the robots.txt protocol, or the "robots exclusion protocol," can be traced back to the mid-1990s, during the early days of web spiders traveling the internet to read websites. Some webmasters became concerned about which spiders were visiting their sites. A file containing directions on which site sections should be crawled and which shouldn't offered site owners the promise of having more control over which crawlers could visit their URLs and how much capacity they were allowed to consume. Since then the robots.txt has grown to meet the needs of modern web designers and website owners.
The current versions of the protocol will be accepted by the spiders and the major search engines to send out to gather information for their respective ranking algorithms. This is a common agreement among the different search engines thus making the commands a potentially valuable, but often overlooked, tool for brands in their SEO reports.
What is robots.txt?
Robots.txt is a series of commands that tells web robots, usually search engines, which pages to crawl and not to crawl. When a search engine lands on a site, it looks at the command for instructions. It can seem counterintuitive for a site to want to instruct a search engine not to crawl its pages, but it can also give webmasters powerful control over their crawl budget.
When writing out your protocol file, you will use simple, two-line commands. The first line says, "user-agent." This portion of the protocol dictates who the instructions apply to, and an asterisk "*", usually referred to as a wildcard, will mean that the command applies to all the web robots. Under the "user-agent" it will say, “disallow.” This tells the robots what they cannot do. If there is a "\", it means that the spiders should not crawl anything on the site. If this portion remains blank, then the spiders can crawl the entire site.
Why would I want to use robots.txt?
Understanding how Google crawls websites will help you see the value in using robots.txt protocol. Google has a crawl budget. This describes the amount of time that Google will dedicate to crawling a particular site. Google calculates this budget based upon a crawl rate limit and crawl demand. If Google sees that their crawling of a site slows down that URL, and thus hurts the user experience for any organic browsers, they will slow the rate of the crawls. This means that if you add new content to your site, Google would not see it as quickly, potentially hurting your SEO.
The second part of the budget calculation, the demand, dictates that URLs with greater popularity will receive more visits from the Google spiders. In other words, as Google stated, “you don’t want your server to be overwhelmed by Google’s crawler or to waste crawl budget crawling unimportant or similar pages on your site.” The protocol will allow you greater control over where the search engine crawlers go and when, helping you to avoid this problem. In addition to helping you direct search engine crawlers away from the less important or repetitive pages on your site, robots.txt can also serve other important purposes:
- It can help prevent the appearance of duplicate content. Sometimes your website might purposefully need more than one copy of a piece of content. For example, if you create a printable version of a piece of content, you may have two different versions. Google has a well-known duplicate content penalty. This would allow you to avoid that.
- If you are reworking parts of your website, you can use robots.txt to hide unfinished pages from being indexed before they have been prepared.
- You also likely have pages on your website that you do not want displayed to the public. For example, this might include a thank you page after someone has made a purchase or submitted a login page. These pages should not appear on a search engine, making it worthless for Google or other search engines to index them.
According to Google, here are some of the most common rulesets for the protocol: 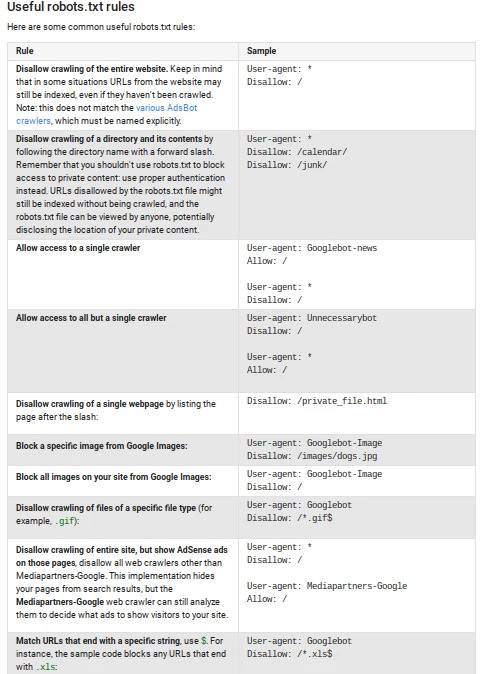
- It is important that while noting the various useful features of robots.txt, you do not try to use the protocol to keep sensitive information private. Think of the protocal as a request, but not a command.
- Although "good" spiders, the ones run by reputable organizations such as Google or Bing, will listen to the protocol's orders, it remains quite possible for crawlers designed by those with more nefarious intentions to ignore the command and crawl the page regardless of the code specified. Pages can also become indexed in other ways. For example, if another site or another page on your own site links to the page, your hidden page could end up indexed.
- When planning out your site infrastructure it's important to make a distinction between your private pages. Are these pages that need to be private and non-discoverable for solely for SEO reasons, or is keeping the content on these pages away from crawlers a security issue - e.g. exposure of sensitive customer data? The value of the robots.txt comes from the SEO strategy, not keeping confidential information private.
How do I configure robots.txt?
Setting up your protocol can be straightforward, but first let’s review what the two parts of the protocol mean:
- User-agent: refers to the crawlers that the text refers to
- Disallow: indicates what you want to block, what the crawler should not read
In addition to these two main portions, you can also use a third portion, labeled ‘allow’ if you need it. This section will be used if you have a subdirectory that falls within a blocked directory. For example, if you wanted to block the majority of a directory but had a single small subdirectory, the fastest way to set this up might be to say: user-agent: * (remember that the asterisk indicates that the protocol applies to all the spiders) disallow: /directory allow: /subdirectory1
This will tell the crawlers to look at this single subdirectory, even though it falls within the larger, blocked directory. If you want to let the crawlers look at the entire site, then you will leave the ‘disallow’ portion blank. If you want to set up your robots.txt to block specific pages, such as your login page or a thank you page, then in the "disallow" portion of the protocol you will put the portion of your URL that comes after the ‘.com’. As you think about the pages that you may want to block, consider these types of content and see if you have any on your site.
- Login pages
- Thank you pages for after someone has downloaded or purchased something
- Needed duplicate content, such as a PDF or printable version of a webpage
- New pages that you have begun to develop, but you do not want search engines indexing them yet
 Although robots.txt looks simple, there are a few rules that must be followed to ensure that the code will be interpreted properly.
Although robots.txt looks simple, there are a few rules that must be followed to ensure that the code will be interpreted properly.
-
- Use all lower case letters for the file name, "robots.txt"
- The protocols must be located in the top-level directory of the web server
- You can only have one "disallow" for each URL on the site
- Subdomains that have a common root domain need different protocol files
After you set up the protocol, you should test your site with your Google Webmasters account. Under the menu there will be a "Crawl" option. Clicking on this will open a dropdown menu, which will include a protocol tester option. If Google says that the text is allowed, it means that your text was written correctly. Robots.txt can be a useful tool in the hands of SEOs who understand the value of controlling how and when spiders crawl their websites. Consider how it might benefit your website and take this next step in SEO.