Knowledge-Based Trust: A New Ranking Factor?
On February 12th eight Google engineers set the search world abuzz by publishing an academic paper entitled Knowledge-Based Trust: Estimating the Trustworthiness of Web Sources that describes how trust and factual accuracy could be used to rank websites in the SERPs. 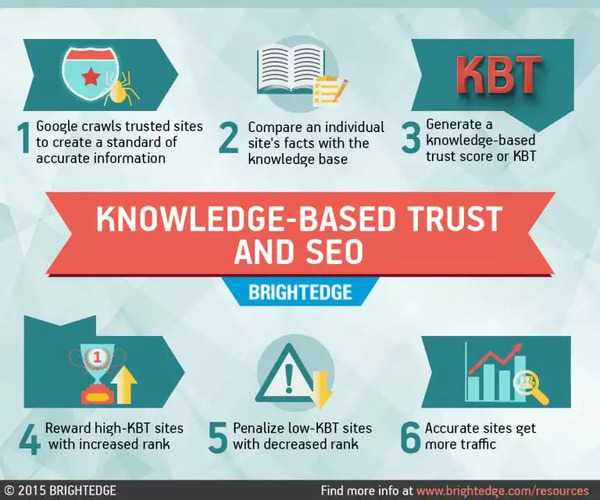
Here is the abstract from the paper:
"The quality of web sources has been traditionally evaluated using exogenous signals such as the hyperlink structure of the graph. We propose a new approach that relies on endogenous signals, namely, the correctness of factual information provided by the source. A source that has few false facts is considered to be trustworthy. The facts are automatically extracted from each source by information extraction methods commonly used to construct knowledge bases. We propose a way to distinguish errors made in the extraction process from factual errors in the web source per se, by using joint inference in a novel multi-layer probabilistic model. We call the trustworthiness score we computed Knowledge-Based Trust (KBT). On synthetic data, we show that our method can reliably compute the true trustworthiness levels of the sources. We then apply it to a database of 2.8B facts extracted from the web, and thereby estimate the trustworthiness of 119M webpages. Manual evaluation of a subset of the results confirms the effectiveness of the method."
We know that Google’s algorithm takes dozens and dozens of factors into consideration when serving up search results, and we know what a lot of those factors are, such as on-page use of keywords and topics, anchor text, domain authority, and PageRank as a measure of a page’s link equity. But trust? Yes, trust as a ranking factor may be coming soon. And it’s easy to understand why. For a full breakdown of how Google's search results pages have changed over time, access our Google SERP Layout Changes research report.
What problem is Knowledge-Based Trust solving?
We all know the problem – a number of sites have great link profiles that are not generally considered trustworthy. Think about all those celebrity gossip sites out there or sites put up by political fringe groups that garner lots of links. You have to wonder -- might it be possible to algorithmically fact-check millions of pages and sites to identify those that are more trustworthy than others? First, Google’s engineers crawled millions of web pages and extracted 2.8 billion trusted facts. Then they compared those facts to data they found on 119 million webpages to estimate the trustworthiness of each page. When they manually checked a subset of their results, they found their algorithm to be highly effective at ranking trustworthiness.
How is trustworthiness of a website defined?
The trustworthiness or accuracy of a web source is defined as “the probability that it contains the correct value for a fact (such as Barack Obama’s nationality), assuming that it mentions any value for that fact. (Thus we do not penalize sources that have few facts, so long as they are correct.)” This suggests the possibility of calculating domain-level trust as well as page-level trust. If the Knowledge-Based Trust algorithm were to be polished and deployed, Google could, for example, crawl millions of pages on The New York Times site and calculate a Knowledge-Based Trust (KBT) score for the entire domain. And presumably a news story published on this domain could rank highly even if it contains a number of facts that cannot be verified algorithmically because the domain is considered trustworthy. We already know through an analysis of URLs published in the In-Depth Articles feature that Google maintains a short list of trusted domains, such as The Wall Street Journal and The New York Times. Now imagine that Google has the ability to algorithmically rank millions of domains for KBT and rank search results accordingly. It may become Panda on steroids.
What will be the consequences of Knowledge-Based Trust?
This new world would seem to favor well-financed domains with strong fact-checking safeguards and niche sites with excellent quality control over more limited subject matter. And the consequences could be far reaching. Consider: if you were the editor of a medical publications site, KBT would increase the pressure on you to think even more carefully about publishing an article on potentially controversial research. Remember that article that kicked off the anti-vaccination movement? And certainly KBT would contribute to the continuing decline of link metrics as a ranking factor. Few will mourn the decreased weight of link metrics. There’s a quote in Google’s paper attributed to Isaac Watts that bears repeating: “Learning to trust is one of life’s most difficult tasks.” It looks like this could usher in a new era of trust on the internet.
