Earlier this month, Google made a subtle change in their Search Console that many overlooked: they changed the max quotas for the number of times you can manually request Google to crawl a URL. Previously, you could request that Google crawl a selected URL 500 times per 30-day period. You could also request that Google crawl a selected URL and all of its directly linked pages 10 times in a 3-day period. The new limits say that you can request a specific URL 10 times per day and a specific URL and the pages it links to directly 2 times per day. 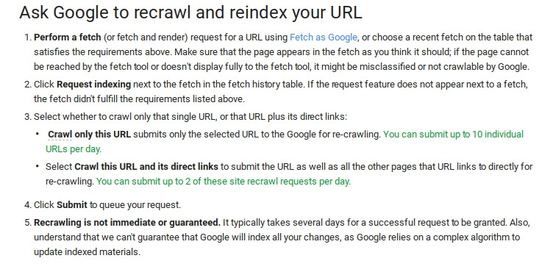 For many marketers, this change will not cause too much concern or change to their SEO reports because they do not submit URLs except when they update the page and few people would do so above the max frequency. BrightEdge always keeps customers apprised of industry changes and this one gives us a chance to reiterate the importance of the fundamentals of site hygiene, taxonomy, internal links, robots.text, and sitemaps and how they influence the crawl, crawl budget, and indexation of site pages.
For many marketers, this change will not cause too much concern or change to their SEO reports because they do not submit URLs except when they update the page and few people would do so above the max frequency. BrightEdge always keeps customers apprised of industry changes and this one gives us a chance to reiterate the importance of the fundamentals of site hygiene, taxonomy, internal links, robots.text, and sitemaps and how they influence the crawl, crawl budget, and indexation of site pages.
What is crawl management and why is it important?
Crawl management describes SEOs’ efforts to control how search engines crawl their sites, including the pages they read and how they navigate the website. Search engine spiders can enter and exit a domain in any order. They might land on your site through a random product page and exit through your homepage. Once the spider has landed on your site, however, you want to ensure that it can navigate your domain easily. The way your site links together will direct the spider to new pages. It will also tell the spider how the site is organized. This helps it determine where your brand’s expertise lies. The crawling of your site remains critical to how your pages rank on the SERP. The spider logs the information about your page, which will be used to help determine your rankings. After you update a particular page, the new page will not impact your rankings until Google returns to crawl it again. Crawl management can also control your reputation with Google. Through techniques like configuring your robots.txt file, you can keep spiders away from certain content, such as duplicate content, and avoid the associated penalties. Google uses a crawl budget to determine how much of your content to crawl and when. According to Google’s Gary Illyes, however, crawl budget should not be a main priority for the majority of sites. For sites that have large numbers of pages, it might be more of a consideration. Illyes reports that Google determines crawl budget based on two main factors:
- How often and how fast the Google spider can crawl your site without hurting your server. If the spider detects that crawling your site slowed it down for users, they will crawl less often.
- The demand for your content, including the popularity of your website as well as the freshness of the rest of the content on the topic.
Webmasters with thousands of pages, therefore, will want to carefully consider their site’s ability to handle the crawls, their site speed, and the freshness of their content to boost their crawl budget.
How do I successfully control crawl management?
Successful crawl management requires building a site that is user and bot friendly, while also carefully protecting pages you do not want the bot to find. Consider the site structure before you design or redesign a website. The taxonomy you select will determine how you categorize and link posts. Linking posts in a purposeful way will help your readers and the bot understand your structure. Remember when creating your links that you want to focus on people first and bots second - the main priority should be providing value and not just trying to make the bot happy. As you build your website you may also find it useful to mark certain pages as "Disallow" within robots.txt to indicate that you do not want search engines to crawl a particular page. This could be for a variety of reasons, such as duplicate content on the page or a page that you currently are building and do not want it included just yet. These commands will let you direct the search engine spiders away from certain text, protecting the reputation of your site.
Crawl management could not be complete without also discussing your sitemap. Google recommends that when constructing a sitemap, you carefully look through each page and determine the canonical version of it to help avoid any duplicate content penalties. You can then submit your sitemap to Google to tell them how to crawl your site. It will help ensure that Google can find all of your content, even if your efforts to build links throughout your site have not been particularly strong.
How will the Google changes impact crawl management?
Google has changed their crawl limit quotas. They have also removed the quota statement on the actual ‘fetch as Google’ space - although the limit still remains clearly stated on the Google help page. These adjustments appear to be in response to abuse of the feature. Google wants to discourage people from manually asking Google to crawl individual pages. It wants people to instead focus on building websites that are naturally crawlable and generating useful sitemaps. This push encourages better-designed websites and an improved experience for users.
What you need to know about the changes to the crawl limits
- Google has changed the quotas for the number of URLs you can manually request Google crawls.
- Google has made these changes to encourage people to create naturally crawlable sites so they do not need to manually request each URL to be crawled.
- Using crawl management best practices including; quality site organization or taxonomy, linking within the site, and using robots.txt, can help you encourage crawling and ensure that the page earns a positive reputation with the bots and with users.
- Creating a sitemap will help you inform Google of your site organization and priorities.
Google continues to push webmasters towards quality site construction. They regularly do so with their algorithm updates that punish poor quality content and reward the valuable. This change with the crawl limits likely has similar intentions. Brands that focus on site organization and prioritize user-friendly layouts will find that this change impacts them minimally. If you previously used this crawl feature on a regular basis, Google wants you to know that the time has come for you to redesign your site.
GSC can help identify problems
Here are a few red-flag use cases where you need to proactively manage the crawlability of selected URLs visible in GSC:
- If a page is generating a 404 error message, the Googlebot will not crawl beyond that page and all of the link equity to that page will be removed. Regaining the link equity will be a hard and long process. 404s are the number-one site hygiene symptom to search out and repair.
- You have orphan pages, but you need this page to be crawled. For instance, this URL is being promoted with paid advertising as the landing page of an integrated-campaign landing page.
- You have made significant changes to a page and want to make sure Google has re-crawled that page immediately, say for competitive reasons.
- You have changed the status of a URL from NoIndex to Index, or vice versa.
- A poorly populated sitemap with either URLs that you do not want to be crawled or missing new URLs that you have published and do want to be crawled.
BrightEdge detects these scenarios for your easily within the platform
- Your first line of defense is BrightEdge’s latest AI-powered innovation–BrightEdge Insights. The Insights product works like another colleague who looks over your shoulder to ensure you stay ahead of any potential site hygiene issues. Insights scans through your website each week and will flag any 404 or No Index issue on the most important pages on your site.
- You can also secure peace of mind by creating a weekly ContentIQ crawl. ContentIQ is an advanced website-auditing solution built for the mobile era. It helps identify website errors, so that your website content stays well-tuned, easily found by search engine bots, and easy to use for your website visitors.
- A sitemap-based ContentIQ crawl will run each week and help surface URLs that are have discoverability issues, such as NoIndex, NoFollow, or Disallowed by Robots.txt. Your review of the weekly ContentIQ results will help you be the first one to know and can take actions easily.
- Create an Orphan Page ContentIQ crawl to ensure you know of any orphan pages on your site. Read our blog to learn more about how to detect Orphan Pages.
Log into the BrightEdge platform today to take advantage of these capabilities.
