Search engine optimization revolves around helping your content rank highly in search engines so that potential customers can find it. There are some moments, however, when you do not want the bots to crawl and rank your pages. In these instances, robots.txt can be a useful resource to help you guide the site crawlers towards the pages you deem more useful.
Create Robots.txt
The earliest form of the robots.txt was developed in the mid-1990s as a way to help site owners control the spiders that visited their websites. It has since been refined and expanded to ensure that it meets the needs of modern website designers. The instructions given in the code will be accepted by the web crawlers from the major search engines, including Google and Bing.
Robots.txt and SEO
Since robots.txt is used to tell search engine bots to not crawl parts of sites, it can sound like the opposite of SEO, but properly using these files can sometimes help the rest of the site rank highly.
For example, some sites generate two pages with identical content, such as a printable version of a web page. Google, however, frowns on duplicate content. To avoid any potential negative marks against your site, it can be helpful to block the Google robots from crawling the printable version of the page.
Robots.txt can also be useful when you are developing a new site. The amount of time it takes Google to index websites can vary widely, from a few days to a few weeks. The timetable is influenced by several factors, such as the popularity of the site. Given the unpredictable nature of how long it takes to get a website indexed, most people want to get their new websites or new web pages fully prepped before they go live. This can help them maximize their SEO capabilities before the Google bots crawl the new content.
Some people will also use the files to help keep personal information private. Since the pages will not be crawled, it will not be displayed to the public on the search engines. It is very important to note, however, that using Robots.txt files does not make the information secure. Think of the Robots.txt as a request-- a closed, but not a locked, door. Google bots will not crawl the information because it will respect the request. There are plenty of malware and spam bots, however, that will completely ignore the request and force their way onto the page. This can result in the publication or theft of this information.
It is also possible for Google to come across the information on the page through other measures, such as when the blocked page is linked to by other websites. Sites that have very sensitive information should make sure it is protected by much more secure measures, such as a firewall.
Using the Robots.txt
Creating a robots.txt file is not a complicated process, but it does have be done precisely to avoid errors. Simple typos in the coding can easily nullify it and you will end up having pages unintentionally crawled. Fortunately, Google has developed a testing tool that allows you to at least check how the Google bots will respond to your robots.txt. There are a few important rules that you need to remember when using this system:
- all the letters of ‘robots.txt’ must be written in the lower case
- the file must be placed in the top-level directory of the web server
- there is only one “Disallow” that can be used for each URL on the site
- subdomains that share a common root domain need to have separate robots.txt files
- you cannot use spaces to separate the parameters of the query.
When one of these rules is broken, then the file will not work as intended. A basic robots.txt file will look like this:

By listing the user-agent as ‘*’, the file tells the spider that this rule applies to all web crawlers. The ‘/’ after the disallow means that this rule applies to all the pages on this particular site. In certain situations, however, you may need to use the file to block a particular portion of the website, such as a directory. In this situation, you will need to replace the ‘/’ with the name of the directory, such as:
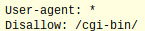
If there is more than one directory that needs to be avoided by the spiders, then the file might look like this:
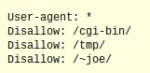
Notice in the above example that there is only one ‘Disallow’ and one directory folder listed on each line. There may also be times when you want to only block certain bots, but the spiders from other sites can come through the page. If that is the case, then the file will have to name a specific bot:
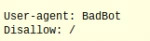
It is important to know that it is also possible to achieve the reverse. If you wanted to allow only one web crawler onto the site but block the rest, then you will need two parts to your file.
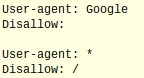
The first part of the file above tells Google that it is allowed to explore the whole site. Since there is nothing after the Disallow, then Google interprets it as open to crawling. The second part of the equation tells the rest of the robots that they cannot enter the site. It is important to note that you can also prevent the robots from exploring specific pages-- it does not have to be entire directories. For example, you can include this in your site code.
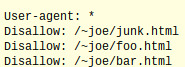
The above example tells all spiders to avoid specific pages. Robots.txt is a valuable resource for those interested in minimizing the exposure of certain parts of their website. Learning how to use these codes can help people optimally construct their sites.
